С-Петербург, 2019 год, AlgoCalc СОДЕРЖАНИЕ
1 Компьютерное зрение, нейронные сети, глубокое обучение 1.1 История развития 1.2 Современное состояние 1.3 Библиотеки глубокого обучения 1.4 Недостатки метода 1.5 Будущее технологии 2 Фреймворк глубокого алгоритмического обучения Заключение Список используемых источников ВВЕДЕНИЕГлубокое алгоритмическое обучение – следующий этап в развитии глубокого машинного обучения сверточных нейронных сетей [1,2], когда граф вычислений представляется в наиболее общем виде не дифференцируемых операций, и соответственно, к нему уже нельзя применять в полной мере метод градиентного спуска, а необходимо использовать инновационные методы метаэвристического поиска [3] для установления не только параметров программных модулей, но и самого вида графа вычислений. Предполагается, что разрабатываемый фреймворк будет, использоваться как практический инструмент применения методов глубокого алгоритмического обучения и алгоритмического исчисления. 1. КОМПЬЮТЕРНОЕ ЗРЕНИЕ, НЕЙРОННЫЕ СЕТИ, ГЛУБОКОЕ ОБУЧЕНИЕ1.1 История развитияАлгоритмы компьютерного зрения, исторически, начинали разрабатываться под конкретную определенную задачу, и были, практически, не переносимы, даже в смежные предметные области. В последующем, разработчики, двигаясь по пути обобщения, стали выделять значимые и повторяющиеся методы в библиотеки обработки изображений, выделения признаков и их классификации. Параллельно появилась и начала развиваться технология нейронных сетей, сначала в ее первоначальном, примитивном виде с одним или двумя полносвязными слоями «искусственных нейронов».
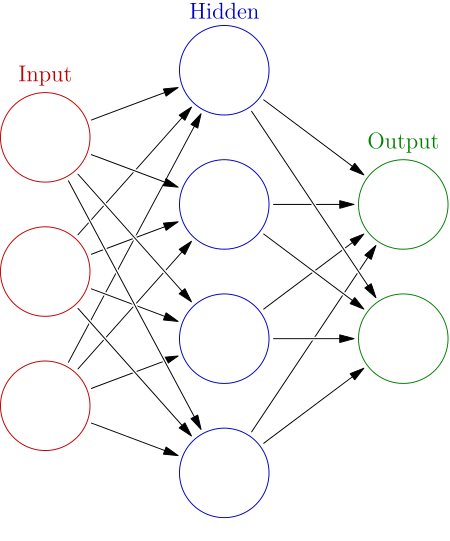
Рисунок 1 – простая нейронная сеть с одним скрытым слоем. В 80-е годы на эту технологию возлагались больше надежды, которые, однако, не оправдались ввиду большой размерности пространства решений и недостаточности вычислительных ресурсов. В промышленности стали применяться более эвристические и конкретные методы, такие как методы опорных векторов на специально выделенных признаках с применением линейных и нелинейных классификаторов. Однако, с начало 2000-х годов и особенно, начиная, с 2010-х ситуация значительно поменялась. Появились новые методики (сверточные нейронные сети) и мощные графические ускорители (GPU), которые хорошо легли на новую парадигму последовательных матричных преобразований. 1.2 Современное состояниеВ последние годы, глубокое обучение (Deep Learning) стало ключевым направлением исследований в машинном обучении и, в частности, в задачах компьютерного зрения. Часто используют и другие названия, по сути, означающие ту же технологию: глубокая нейронная сеть, сверточная сеть, граф вычислений, дифференцируемое программирование. Суть технологии заключается в очень ограниченном использовании слоёв полносвязной нейронной сети, которые либо вообще не применяются (полностью сверточные сети) либо используются только на конечном этапе, когда размерность пространства признаков сильно уменьшена предварительными преобразованиями. Вместо этого используется последовательность некоторого набора простых многомерных матричных (тензорных) преобразований в виде фильтров, сверток, усреднений, суммирований и т.д. Каждое такое последовательное преобразование имеет некоторый набор параметров. Например, для свертки 3х3 таких параметров будет, соответственно, 9. Для последовательности из двух таких слоев, различных комбинаций параметров будет 9 * 9 = 81, а для трех уже 9 * 9 * 9 = 729. 
Рисунок 2 – алгоритм простейшего фильтра-свёртки 3x3. Современные архитектуры сверточных сетей могут иметь десятки слоев. Суть преобразований в слоях заключается в последовательном выделении иерархических признаков на изображении и переходе от более низких уровней абстракции к более высоким. Задача программиста – разработать на основании своих знаний и опыта архитектуру сети для конкретной задачи, т.е. определенную последовательность преобразований (вычислительный граф), подобрать обучающие наборы данных и запустить процесс машинного обучения. 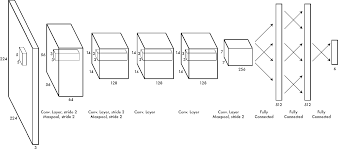
Рисунок 3 – пример архитектуры сверточной нейронной сети с двумя финальными полносвязными нейронными слоями. Задача компьютера на этапе обучения – найти оптимальный набор параметров свёрточной сети, а также набор весов полносвязных нейронных слоев, если они были заданны для финального этапа графа вычислений. При этом применяются различные методы оптимизационного поиска, но в основном используются относительно быстрые методы обратного распространения ошибки и коррекции весов в направлении убывания градиента передаточной функции по параметрам на каждом слое. В результате обучения на наборе данных сеть учится, например, распознавать и классифицировать изображения по отдельности или в контексте. 
Рисунок 4 – набор обучающих данных CIFAR-10 1.3 Библиотеки глубокого обученияНа текущий момент имеется большое количество программных фреймворков – инструментов и библиотек машинного глубокого обучения для задач компьютерного зрения, и их число постоянно растет. Однако, большинство из них имеет исследовательский, академический характер и мало пригодны для промышленного применения. Большинство написано на языке Python, например, – достаточно мощный фреймворк TensorFlow [4] от компании Google. Представляют также интерес библиотеки, написанные на языке Си и имеющие свободный доступ к исходным кодам. Таковой является, например, библиотека DarkNet [5] и разработанная на ее основе технология компьютерного зрения реального времени YOLO – You Only Look Once. 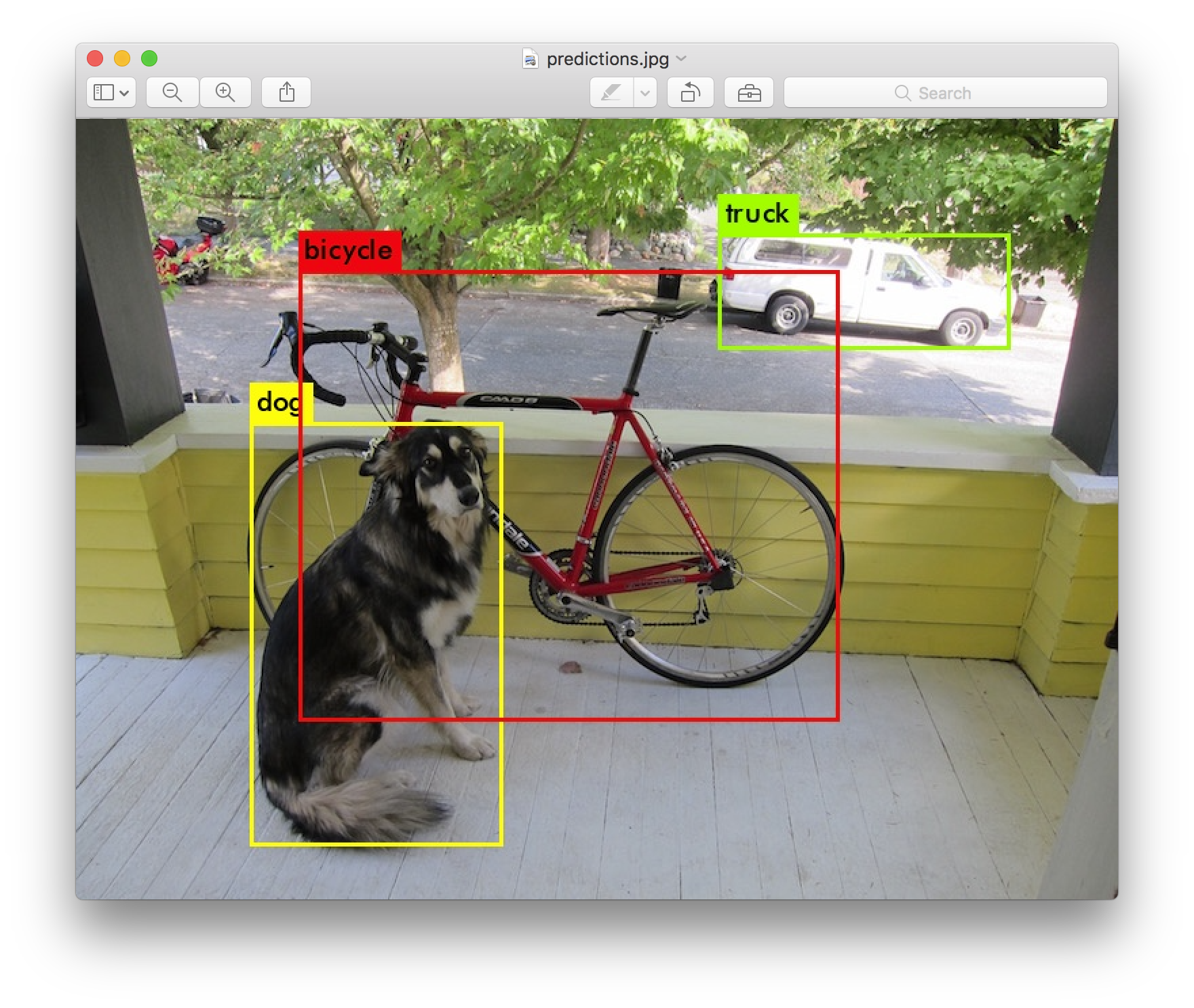
Рисунок 5 – результат работы алгоритма YOLO. Однако и в этом случае применимость технологии ограничена ее принципиальными недостатками, описанными с следующем параграфе. 1.4 Недостатки методаПо сути, вычислительный граф сверточной нейронной сети (СНН) – это простейшая программа, состоящая из последовательных геометрических преобразований в многомерном матричном пространстве. При этом, для используемого метода градиентного спуска важным является гладкость этих преобразований и, соответственно, дифференцируемость. Понятно, что таким образом сильно ограничивается набор возможных алгоритмов. Например, нельзя использовать любые циклы и условные операторы. Кроме того сам метод градиентного спуска применим только для поиска локального минимума, и чтобы найти глобальный экстремум необходимы дополнительные алгоритмические корректировки. Найденное решение, т.е. архитектура сети и ее параметры обычно фиксированы для конкретной задачи и в случае расширения технического задания необходимо, практически, начинать структурирование и обучение с нуля или, по крайней мере, с довольно глубокого слоя обучения. Нет накопления обобщающих знаний, небольшие изменения в ракурсе трехмерных объектов существенно ухудшают статистику распознавания [6]. 2. ФРЕЙМВОРК ГЛУБОКОГО АЛГОРИТМИЧЕСКОГО ОБУЧЕНИЯ
Будущее развитие видится в направлении обобщения графа вычислений от простых гладких
матричных преобразований к более универсальным алгоритмам, с выделением наиболее
продуктивных частей последовательностей в библиотечные процедуры с учетом типизации
их входных и выходных параметров. Автоматически созданные в процессе машинного
обучения библиотеки процедур будут являться, по сути, единицами обобщающих знаний в
предметной области и основой для их дальнейшего неограниченного расширения. Конечно,
такие алгоритмы, в общем случае, не будут дифференцируемы и, следовательно, для поиска
их параметров, а также и для поиска самой архитектуры сети нельзя применять методы,
основанные на предположении о гладкости преобразований. Наоборот, необходимо развивать
общие эволюционные методы поиска структур и их параметров, например – генетические,
эволюционные, метаэвристические алгоритмы. При этом важно правильно сформулировать и
задать модель для таких вычислений. Например, это может быть стековое представление,
где есть одна глобальная переменная – стек и над последовательностями операторов
можно выполнять простые операции преобразований и выделения процедур для библиотеки.
Конечно, что касается, особенно, приложений компьютерного зрения, то матричные гладкие
преобразования будут и дальше составлять значительную часть графа вычислений, а значит,
к отдельным его частям возможно применение разработанных ранее методов градиентного
спуска. ЗАКЛЮЧЕНИЕ
Рассмотренный выше проект создания и развития фреймворка глубокого алгоритмического
обучения COMPOT позволит, существенно продвинуться
вперед в направлении развития компьютерных и технологических моделей.
В дальнейшем, применение фреймворка COMPOT
в контексте алгоритмического исчисления позволит получать
новые знания в сфере алгоритмических методов научно-технических и фундаментальных
исследований.
СПИСОК ИСПОЛЬЗУЕМЫХ ИСТОЧНИКОВ
|